Hi everyone! I hope someone can clarify a situation for me. I’m using Linstor with Cloudstack, and I created a resource group for it with the parameter --place-count 2. Most of my replicas have two data replicas and one tiebreaker. However, I recently noticed that several replicas are missing tiebreaker and instead have a diskless one. I also have a couple of replicas with missing tiebreaker but have two diskless replicas. I’d like to know if this is a normal situation to have a diskless replica instead of a tiebreaker, and if I having two diskless replicas can it be a problem, as it results in an even number of replicas. If this is not a normal situation, how can I fix it?
Full explanation: Differences in DRBD resources - #6 by ghernadi
In short, you’re fine.
If Linstor has created a “tie breaker” resource by itself then it can remove it when no longer required. But if Cloudstack has created a “diskless” resource somewhere, Linstor will never delete it by itself.
An even number of participants is not a problem either. With 4 participants the quorum is 3, the same as if there were 5 participants. This means with 4 participants it can only withstand loss of one member, but that’s the same as with 3 participants.
Thank you very much for you explanation, its all clear for me with differences of resources now. But, regarding the number of resources, could you please answer the following question? If, due to a network issue, my cluster splits in half, and each side has one diskfull and one diskless, how will the quorum work in this case?
I just checked the drbdadm status of the resource, and I understand now. Additional diskless resource is simply not taken into account. Status always shows three resources. @candlerb Thank you once again for your help. Now it’s all clear to me).
That was a good point - thanks for answering it.
I finally decided to check all resources and discovered that some of them, which had 4 replicas, also showed 4 devices in the drbd status. And this situation looks not safety. I also noticed that the Сloudstack plugin for Linstor seems to be actually deleting diskless devices. Additional diskless devices would disappear every time I performed a migration to a node with that device, and then migrated to any other node. After this process, the number of replicas normalized on each such resource. Now, with each migration to a node without data, a diskless device is creating there, and the excessive diskless device is automatically removing. In one instance, I even observed that the diskless device became a TieBreaker again.
Hi @rp9 ! It looks like I need your help again)). If you will have time, could you clarify this for me. Can it be a bug, or if I’m just don’t know how Linstor works?)) I would also like to add some information. A couple of weeks ago I performed an upgrade to ACS 4.19.3 and the latest version of Linstor, DRBD, and all related components. Can it be a reason of this inconsistency?
According to this article, you’re supposed to add diskless tiebreaker nodes to make an odd-numbered set, which makes sense.
I see Linstor automatically create tiebreakers when there are two resource replicas, but not for other even numbers of replicas.
Please, correct me if I’m wrong, but as I understand it, a LINSTOR tiebreaker node is only useful if you have just two nodes, making it impossible to create a third resource for quorum purposes. In my case, it wouldn’t help. It doesn’t matter how many nodes you have, but rather how many replicas LINSTOR is maintaining. In my case, for some reason, LINSTOR was holding extra devices, and the drbd status command was taking all four devices into account.
Now, let’s model a situation. Let’s say I do have a dedicated tiebreaker node. A virtual machine starts on one of the nodes where there’s no data. At that moment, we have four devices. A short network problem occurs that splits the cluster in half. On one side we have a diskless node and a diskfull node, on the other side we have a tiebreaker node and a diskfull node. The virtual machine connected to that disk remains running on the tiebreaker side. On this side, there are two replicas, so DRBD considers that the majority is on their side and doesn’t stop I/O. On the other side, the situation is the same: there’s a majority. But in addition, the CloudStack management stayed on the side where the virtual machine wasn’t running. HA launches the virtual machine on this side. After that, the network problem resolves, the cluster recovers, and we have two running instances of the same virtual machine, two inuse devices in Linstor resource, and classical split-brain scenario.
There isn’t any concept in Linstor of a "tiebreaker node” - but there is a “tiebreaker resource”.
If you have a three-node cluster, and the third node has no storage pools apart from DfltDisklessStorPool, then the only thing you can create on that third node is diskless resources - so you can call it a “tiebreaker node” if you like; but you can also use these diskless resources to access storage, so it’s not limited to just tiebreaker functionality. For example, you could run VMs there, with storage backed on the other two nodes.
If you have a cluster with 3 or more nodes, and you create a resource definition with only two resources, a third “Tiebreaker” resource is added automatically on a random node. If you manually add a third resource to that resource definition, then the tiebreaker is no longer needed and is removed.
And if you have a two-node cluster, then no tiebreaker resources will be created, as there’s nowhere for them to go.
Now, let’s model a situation. Let’s say I do have a dedicated tiebreaker node. A virtual machine starts on one of the nodes where there’s no data. At that moment, we have four devices.
I’m afraid you’ve lost me there. Please describe your cluster more clearly. How many nodes does it have? Which ones have storage pools defined? Which ones are where VMs run? Which one are you calling a “dedicated tiebreaker node”? And when you create a VM, what’s the placecount in the resource group?
If your cluster has 3 or more nodes with storage pools, then there’s no need for an additional node without storage (what I believe you’re referring to as a “tiebreaker node”), because these tiebreaker resources can be created anywhere. They will only be created if a particular resource definition has only two replicas (resources).
Looks like I don’t understand you previous post correctly,
I thought you proposing me to orginize one “tiebreker node“, to avoid problem in my situation.
I have now 4 nodes, all of them with storage pools, all added to linstor, all of them compute and running vm. No any “dedicated tiebreaker node”. My placecount - 2.
But for some reason, I have found some resources with 4 replicas? and all 4 replicas was shown in drbdadm status. But after my manual migrations of related vm, this recourse count became to normal 3. And now, when I making migrations on node without data, it’s create a diskless resource and delete unused, diskless resourse on another node. And I think now its working correct. But whats the reason, it was in incorrect state with 4 replicas. If its happens once again, and I will have network issue in this time. It will be a problem. That’s my question.).
I have created a monitoring check of resource count using Zabbix, and I recently got an error stating that I have a resource with 4 devices. I noticed this resource was related to a VM which was recently migrated by the CloudStack DRS plan. After the DRS plan execution, I have:

But when I manually migrate this VM to node2, everything returns to normal.

After manually migrating it back to node1.

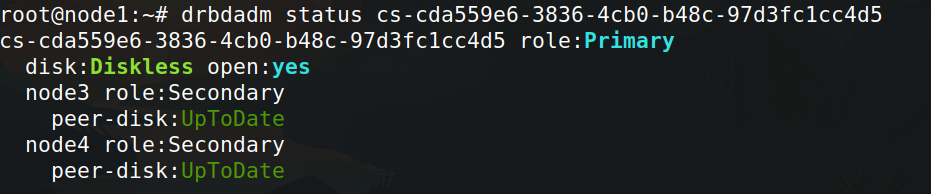
Maybe I still don’t understand something, but it looks like I need to create a bug report)
This behavior is related to DRS migrations by CloudStack.
This looks like, cloudstack drs wouldn’t call “disconnectPhysicalDisk” on the removed agent.
Otherwise the cloudstack plugin would remove the exceeding diskless, as we see on manual migration.
I mean this isn’t a big problem, as everything should work as is, except there is an additional diskless, so rather minor.
Hi @rp9 ! And thanks for you reply. But in the scenario I described above, where a cluster could potentially split in half, wouldn’t that cause a split-brain situation? How would DRBD determine which side has the majority? I understand that fencing is the responsibility of the orchestrator, but isn’t this a potential problem?
Quorum is there to prevent split-brain, so no, you won’t end up in a split brain.
I think in the worst case just both sides wouldn’t get quorum and no one could access the data.
AFAIK even the nodes know which one was last primary and that one would continue running, if the other members can not gain quorum again.
maybe this helps a bit for understanding: DRBD Quorum Implementation Updates - LINBIT
Thank you all guys so much for the explanation and the links, it’s much clearer now, and I feel more confident. @rp9 Do you think I should create a bug report or improvement request on the CloudStack GitHub to improve the consistency of DRS and the Linstor plugin’s operation?
Yeah, you can create a bug report.
It would be cool if you could include agent (DEBUG) logs from the agent that should remove the (diskless) resource and management server logs of that time.